

Re-architecting Core Data in TextNow

TextNow Developer
April 21, 2017
Share



Browse categories

Re-architecting Core Data in TextNow
TextNow uses Core Data extensively for data storage. After 6 years of use within the application among many API changes, our Core Data layer needed a revamp. Apple has better Core Data architectural models, and so our goal was to identify the inefficiencies in what we were doing and move to a better and more efficient architecture.
I work on the TextNow Foundation squad and am responsible for ensuring the core parts of our products are well-architected and aligns with the best practices when it comes to iOS development.
Apple’s queue-based Core Data contexts have been in production for quite some time now, but we were still using the older thread-confined contexts. Now with iOS 9 and 10, Apple wants to deter developers from using thread-confined contexts. Most queue-based architectures are intended for optimizing usage of resources, so this was one of the biggest opportunities for us to move into a queue-based Core Data architecture.
The Original Architecture
Core Data contexts are an in-memory representation of the persistent store. Changes to in-memory context can be aggregated before saving to the backend, or discarded altogether like a scratch pad.
We were relying on contexts that were thread-specific. To do any backend work, one would have to create a context for the current thread, use the context to modify managed objects, and then merge the changes into the main context which is running on the main thread. As you can see, with this architecture in place if parallel operations were to be run at the same time then not all contexts would be able to merge their changes into the main context simultaneously. A thread-level synchronization would be required, and so we have an @synchronization block around the Core Data saves.
Also, each time data merges into main context, it would be run on the main thread along with other UI-related workloads. So heavy usage of core data in the backend would result in bad UI performance.
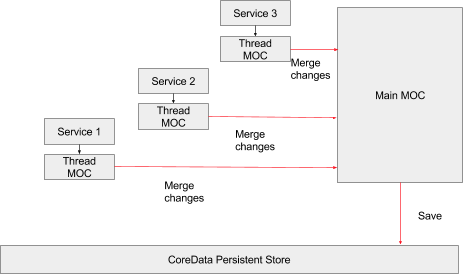
We have over 80 different NSOperations that work in the backend. Some access our backend API, some modify the Core Data entities locally, and some others do both. If data needed to be passed around from one operation to another, we would have to merge the data into main context and then spin up a new thread-specific context from the main context and retrieve the Core Data objects by their managed object id. This again was one more inefficiency waiting to be optimized.
All the NSOperations ran in a parallel (5 concurrent operations), but when it came to Core Data changes each context would merge its changes to the mainContext using a thread-level synchronization. This was like a bunch of super charged engines trying to ram into a narrow gully to get across.
One more thing about Core Data is how picky it is about running operations on the context only on the thread where it was created. So if you ever retrieve a managed object on one thread and pass it around for another thread to work on, Core Data will show its dislike by awkwardly crashing on you. A rather hard crash to reproduce. It will eventually show up on the App Store builds when used by millions.
So as a developer, it was all the more critical to understand Core Data threading model and be super cautious about how and where contexts were being used.
Implementing The New Architecture:
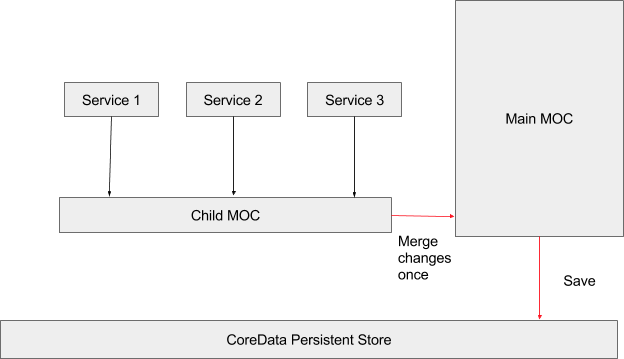
With the new queue-based Core Data contexts, all Core Data related operations are offloaded onto the Core Data queues. This is the main requirement of queue-based Core Data contexts. So rather than using the current thread specific context to do the Core Data work the Core Data queue would decide how to efficiently work on Core Data transactions.
This offloading of work was now done by a queue manager which, depending on the type of NSOperation, would either run them in a regular queue or off-load them to the Core Data queue. To ensure we could identify the operations that were Core Data specific, we created a new base class AuthenticatedDataServices and re-classified (i.e. changed the base class) of our operations using that worked on Core Data. This class type was then used to determine how we would handle the workload.
Since it was hard to extract only Core Data work from other types of work done by an NSOperation, the entire operation’s “start” method was being offloaded into the Core Data queue.
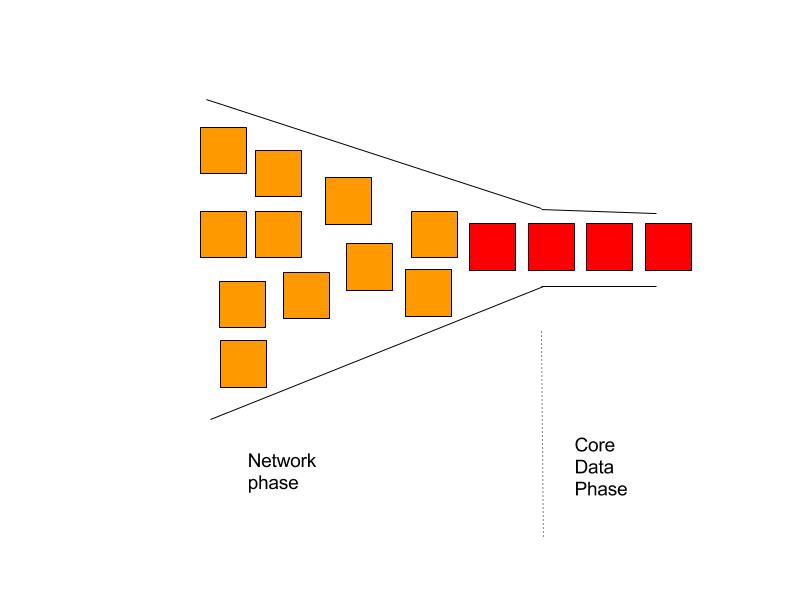
Core Data queues are serial queues, so all work gets done in a serial fashion. As you can see now with the new architecture we were losing the parallelism of the NSOperations they had before. They are now being serialized by the Core Data queues. Obviously, this was two steps forward and one step back in improving our architecture. We had to get back the lost parallelism into the new architecture.
On further inspection into each operation, we identified a pattern of usage. There was network-related work and Core Data-related work in each operation. So we started breaking down the operation into two sub-operations — the network part, and Core Data part. Now we could parallelize the network parts and serialize the Core Data parts. This required some code level changes to extract out network portions vs Core Data portions into respective methods. With that change the service manager could just queue the network portion into a regular parallel queue and enqueue the Core Data portion to the Core Data queue.

Advantages of Re-architecting
With the new architecture in place, we could now aggregate changes on the queue based contexts and merge into the main context only when necessary. This resulted in less interference with the main UI activity since the merges are run on a background thread. This kind of underlying merging strategy which could be controlled and tweaked was central to the new architecture. With the new architecture in place, we could now remove thread level synchronization that was used in code extensively to control saves into Core Data.
On top of everything, new developers working with Services and Core Data layers did not have to worry about the context to use or the thread to run all Core Data work. This was built into the code for them!
At TextNow we are solving interesting problems like this everyday. If this gets you excited and you like challenging problems like this, check out some of our Engineering job openings.
Credits : Fang Chen for helping me through this architecture.



.png)